图 " 字符串匹配算法示意图字符串匹配算法的执行进程如下:从句子的第一个词性开始,依次插手其后的一个词性构成词性串,然后判定是否切合根基名词短语法则。假如直到句末(即由一个句子的所有词性构成的词性串)都不切合根基名词短语法则,则认为第一个词性不包括在名词短语内。然后从第二个词性开始,反复上述进程。假如从某词性开始,依次插手后头的词性构成的词性串满意根基名词短语的法则,则取最长的词性串构成的根基名词短语作为最后的功效。
(2)对付界线统计要领后没有识别出来的根基名词短语:取出没有识别出来的根基名词短语的子串(由识别出来的根基名词短语离隔),对每个子串应用字符串匹配算法(利用法则集 !2)。该算法从左边第一个词开始,把它的词性依次与之后的每个词性毗连,看可否构成根基名词短语(到筛选后的法则集 !2 中去查),把能构成根基名词短语的最长的词性串作为识别出来的功效。图 2 暗示界线统计后获得的一个错误功效经字符串匹配算法的校正进程:句子:. . . Deeply / RB[ingrained /JJ in / IN both /PDT the / DT book / NN review/ NN]. . .。
回收本计策获得的英语和汉语名词短语识此外精确率都超出今朝报道的最好功效。
图2 中,第一个词词性 JJ 和第二个词性 IN 与其后的词性构成的词性串都不能构成根基名词短语;而第三个词性 PDT 和它后头的词能构成根基名词短语,取最长词性串 PDT DT NN NN 构成的根基名词短语作为最后的功效,识别出的根基名词短语的开始界线为 PDT 地址的词,竣事界线为后一个词性为 NN 的词。功效改为:Deeply / RB ingrained /JJ in / IN[both / PDT the / DT book / NN review/ NN]。
要害词 英语根基名词短语识别,汉语根基名词短语识别,快速移植,标记替换
l 界线统计和词性串校正相团结的英语根基名词短语识别图 l 是界线统计和词性串校正相团结要领的系统流程图。图 l 中左半部门是回收界线统计的流程,右半部门是回收词性串法则校正的流程。
鉴于此,我们设计了如下两种校正方案:
识别根基名词短语是自然语言处理惩罚规模很是重要的子任务。英语根基名词短语长短递归的名词短语,海表里有许多研究人员举办了英语根基名词短语识此外研究事情,他们利用的要领概略上可以分为基于法则和基于统计的两种。词性串法则[1]和基于转换错误驱动的要领[2]是两个典范的基于法则的要领。但基于转换错误驱动的要领获取法则的时间很漫长。Church 的界线统计要领[3]、荀恩东的统一统计模子[4]、Zhou 的错误驱动的隐马尔可夫要领[5]、基于影象[6]和支持向量机 SVM[7]等要领都是英语根基名词短语识此外典范要领。连年来,海内的一些研究人员举办了汉语根基名词短语识此外研究。赵军[8]用基于转换错误驱动的要领对汉语根基名词短语举办识别。以下研究者在组块阐明中包括根基名词短语的识别:周强[9]先容了汉语句子的组块阐明体系,并引入了词界块和身分组的观念,将身分识别问题从完整的句法阐明任务中疏散出来;张昱琪[10]和李珩[11]别离把基于影象和 SVM 的要领运用到汉语语块识别中,取得了较好的识别功效。
通过以上阐明发明,英语根基名词短语识别回收的要领总体上可分为基于法则和基于统计的要领以及应用呆板进修的要领。一些主要要领的功效见表1。从表 1 不丢脸出,纯真的法则要领和纯真的统计要领不如法则和统计相团结的要领。而汉语根基名词短语识此外要领大多是把识别英语根基名词短语的要领在汉语上从头实现一次,这样做的功效是挥霍时间和人力。英语根基名词短语技能相对汉语要成熟,假如有一种技能能迅速地用识别英语短语的措施识别汉语,将大大加速汉语短语识此外速度。
图 ! 本系统的系统流程图从练习语料中统计构成根基名词短语的词性串组合,!l 由呈现次数大于 l 的词性串构成(共l 707个法则),!2 由呈现次数大于 5 次的词性串构成(共l l62个)。法则的形式如 DT CD CD NNPS,界线统计时参考当前词的词性和前一个词的词性。颠末对界线统计获得的功效错误阐明,发明白三类错误:(l)只是识别出了词性为“NN”或“NNS”的一个词,丢掉了它前面的修饰身分。例子:declining[mortality]。
(2)有些根基名词短语基础就没有被识别出来。例子:. . . from/ IN[ / 3. 03 / CD billion / CD]a / DTyear/ NN earlier/ RBR. /。(3)识别出的短语内部包括有不属于根基名词短语的词。例子:. . . Deeply / RB[ingrained /JJ in / IN both / PDT the / DT book / NN review/NN]. . .。
鉴于英语和汉语根基名词短语识此外问题,本文提出了一种新的英语根基名词短语识别要领———界线统计和词性串校正相团结的要领,该要领把根基名词短语识别分成主次理解的两部门:一部门是界线统计,另一部门是词性串法则校正。词性串法则的获取是通过统计练习语料中构成名词短语的词性串组陈纪律而获得,相对付基于转换错误驱动的要领要简朴迅速。并把识别英语根基名词短语的措施举办简朴的标记替换(时间不高出 1 小时),然后用来识别汉语根基名词短语,到达了从英语根基名词短语识别向汉语根基名词短语识别快速移植的目标。
本文的根基名词短语识别特点如下(:1)同时思量根基名词短语的界线特点和构成根基名词短语的词性串纪律。(2)对界线统计功效的查对利用所有的词性串构成的法则,以担保不漏掉正确功效,而接纳漏掉的名词短语,则利用筛选后的词性串法则,以担保接纳的精确率。(3)汉语根基名词短语的识别完全差异于传统的要领,而是回收从识别英语根基名词短语的措施举办移植,节减了人力和时间。
(l)对付界线统计要领获得的根基名词短语:假如识别出的根基名词短语的词性为“NN”或“NNS”的一个词可能词性串在法则集 Rl 中无法找到,插手左边的两个或一个词的词性看是否能构成根基名词短语,假如不能构成根基名词短语对该词性串应用字符串匹配算法(见图 2)。
2 英语根基名词短语识别向汉语的快速移植英语根基名词短语和汉语根基名词短语的界说很是相似,所以我们提出回收快速移植的计策来识别汉语根基名词短语。本文中的汉语根基名词短语的界说如下:汉语根基名词短语长短递归的名词短语,它包罗所有依赖于一其中心名词的词。修饰名
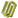 |
更多内容,请点击下载附件!
|
摘 要 提出了界线统计与词性串校正相团结的英语根基名词短语识别计策,使英语根基名词短语识此外 F 测度值到达了 96. 90%,高出今朝报道的最好功效。通过简朴的标记替换(修改措施的时间不高出 1h),用识别英语根基名词短语的措施实现了对汉语根基名词短语的识别,汉语根基名词短语识此外 F 测度值到达了 95. 04%。该技能可推广到对多种短语的快速移植。
图 2 中虚线暗示词性串不能构成根基名词短语,实线暗示能构成根基名词短语。
